轻量化网络设计
[[TOC]]
深度神经网络模型被广泛应用在图像分类、物体检测等机器视觉任务中,并取得了巨大成功。然而,由于存储空间和功耗的限制,神经网络模型在嵌入式设备上的存储与计算仍然是一个巨大的挑战。
轻量化网络设计旨在使用更少的参数达到重量级网络的效果。轻量化网络在训练(例如 ,分布式训练)和部署(例如,部署在移动端)上具有很大的优势。理论上轻量的浅层网络特征提取能力不如深度网络,训练也更需要技巧。不过假设保证有足够多的训练的数据,轻量网络训练会更加容易。
轻量级卷积网络设计往往具有下面的某些特点:
- 再各个层中会技巧性地使用卷积
- 降低前向传播过程中的通道数
- 减少不必要的shortcut连接和ReLU层
- 使用Group Normalization 替换 Batch Normalization
- 网络的层数较少
- 在网络的浅层使用空洞卷积和深度可分离卷积替换普通的卷积
轻量化模型主要围绕减少计算量,减少参数,降低实际运行时间,简化底层实现方式等这几个方面,提出了深度可分离卷积,分组卷积,可调超参数降低空间分辨率和减少通道数,新的激活函数等方法,并针对一些现有的结构的实际运行时间作了分析,提出了一些结构设计原则,并根据这些原则来设计重新设计原结构。
除了直接设计轻量的、小型的网络结构的方式外,还包括使用知识蒸馏,低秩剪枝、模型压缩、基于神经网络架构搜索(Neural Architecture Search,NAS)的自动化设计神经网络等方法来获得轻量化模型。
真的要研究轻量的CNN设计,可以从AlexNet说起。
瓶颈层(Bottleneck Layer):始于ResNet
Bottleneck layer又称之为瓶颈层,使用的是的卷积神经网络。之所以称之为瓶颈层,是因为长得比较像一个瓶颈。
如上图所示,经过的网络,中间那个看起来比较细。像一个瓶颈一样。使用 卷积处理后可以大幅减少计算量。
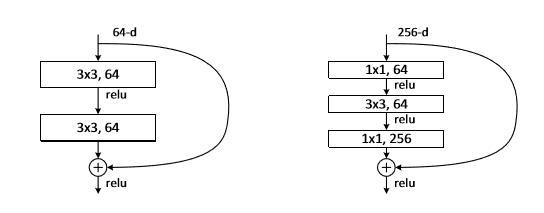
上图:有bottleneck和没有bottleneck的ResNet模块对比。使用瓶颈层,使得ResNet在保持上一层channel数量的同时降低下一层中卷积的运算量。瓶颈层并不总有用,在带有残差结构的网络中瓶颈层尤为有效。
在后面,我们还会聊到MobileNet V2中提出了一种称为线性瓶颈(Linear Bottleneck)层的结构。
VGG:使用代替
VGG(在这篇文章中进行了讲解)在网络中有一个有趣的设计,就是使用两个卷积取代卷积:
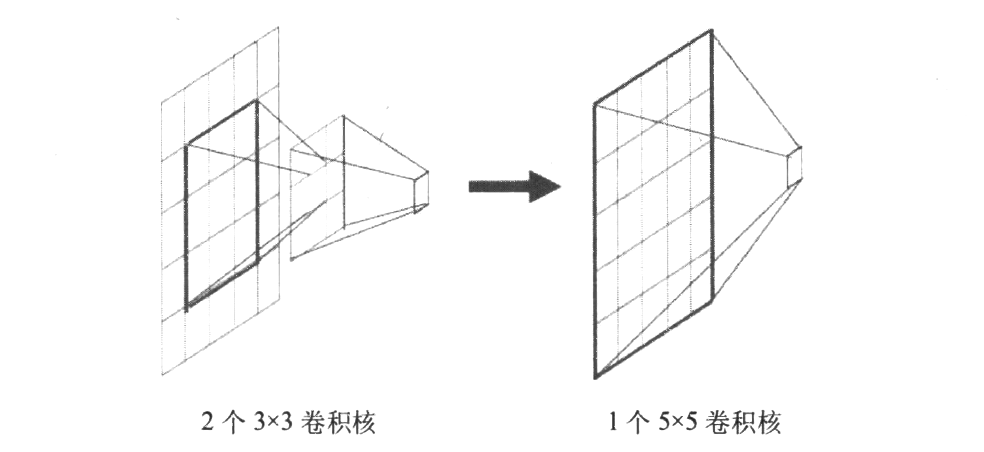
将多个3x3卷积核的卷积层堆叠在一起是一种非常有趣也非常有用的设计,这对降低卷积核的参数非常有帮助:在下采样特征提取的角度来看,这两者的效果是相同的:两个卷积或是一个卷积都会使当前位置的像素和周围范围内的像素产生关联。
不过两层卷积产生的参数量(也就是两个核的大小)是,而一个卷积带来的参数量是。也就是说,在获得相同感受野的情况下,两层卷积所占的参数量更少。同时,这种设计也会加强CNN对特征的学习能力(你可以简单理解为多了一个核,学习能力有所增强)。这种设计可以被推广用来替代更多的层,例如,你可以三层卷积代替一层卷积,以此类推。
分组卷积(Grouped Convolution)
分组卷积是标准卷积的变体:

上图:普通的卷积

上图:分组卷积。假设卷积核尺寸为,和用于表示输入的空间尺寸,表示输入的通道数,表示输出的通道数。则分组卷积将输入特征通道分为组,并且对于每个分组的信道独立地执行卷积,分组卷积计算量是,为标准卷积计算量的。
始于AlexNet
Grouped Convlution最早源于AlexNet(在这篇文章中进行了讲解)。AlexNet在ImageNet LSVRC-2012挑战赛上以绝对优势取得了冠军,不过当时AlexNet训练时所用GPU GTX 580显存太小,无法对整个模型训练,所以Alex采用Group convolution将整个网络分成两组后,分别放入一张GPU卡进行训练:
ShuffleNet V1
ShuffleNet系列是轻量级网络中很重要的一个系列,ShuffleNetV1提出了channel shuffle操作,使得网络可以尽情地使用分组卷积来加速。
ShuffleNet的核心在于使用channel shuffle操作弥补分组间的信息交流,使得网络可以尽情使用pointwise分组卷积,不仅可以减少主要的网络计算量,也可以增加卷积的维度:
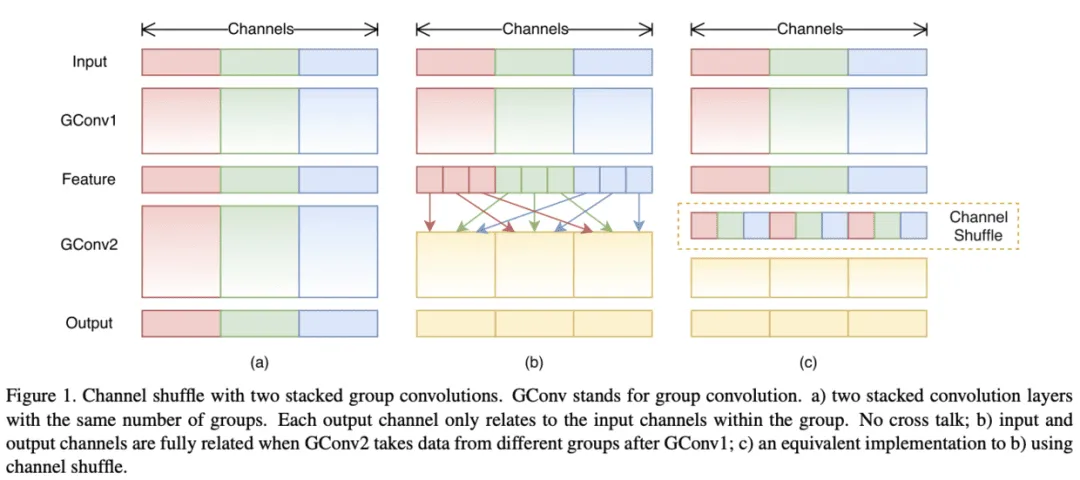
上图:channel shuffle(b)(c)与普通分组卷积(a)。
在目前的一些主流网络中,通常使用pointwise卷积进行维度的降低,从而降低网络的复杂度,但由于输入维度较高,pointwise卷积的开销也是十分巨大的。对于小网络而言,昂贵的pointwise卷积会带来明显的性能下降,比如在ResNext unit中,pointwise卷积占据了93.4%的计算量。因此,本文引入了分组卷积。但是分组卷积可能导致分组间的信息交流缺乏。
本文探讨了两种ShuffleNet的实现:
- 图中(a)是最直接的方法,将所有的操作进行了绝对的维度隔离,但这会导致特定的输出仅关联了很小一部分的输入,阻隔了组间的信息流,降低了表达能力。
- 图中(b)对输出的维度进行重新分配,首先将每个组的输出分成多个子组,然后将每个子组输入到不同的组中,能够很好地保留组间的信息流。
(b)的思想可以简单地用channel shuffle操作进行实现,如(c)所示, 假设包含组的卷积层输出为维,首先将输出reshape为 , 然后进行转置(transpose) , 最后再打平(flatten)回维。
ChannelNets:channel-wise卷积建立组间信息交流
论文提出channel-wise卷积的概念,将输入输出维度的连接进行稀疏化而非全连接:

区别于分组卷积的严格分组,以类似卷积滑动的形式将输入channel与输出channel进行关联,能够更好地保留channel间的信息交流。
基于channel-wise卷积的思想,论文进一步提出了channel-wise深度可分离卷积,并基于该结构替换网络最后的全连接层+全局池化的操作,搭建了ChannelNets。
IGC系列网络:分组卷积的极致运用
IGC系列网络的核心在分组卷积的极致运用,将常规卷积分解成多个分组卷积,能够减少大量参数,另外互补性原则和排序操作能够在最少的参数量情况下保证分组间的信息流通。
IGC V1
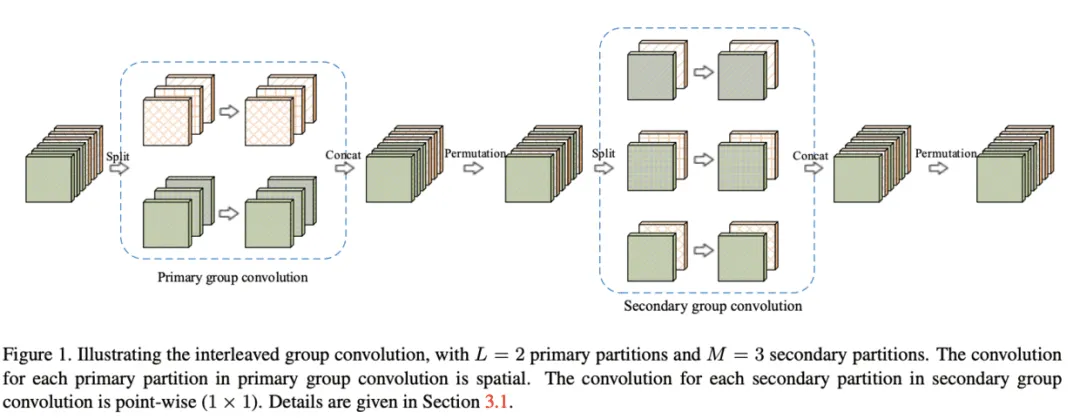
Interleaved group convolution(IGC)模块包含主分组卷积和次分组卷积,分别对主分区和次 分区进行特征提取, 主分区通过输入特征分组获得, 比如将输入特征分为个分区, 每个分区包含维特征,而对应的次分区则分为个分区, 每个分区包含维特征。主分组卷积负责对输入特征图进行分组特征提取, 而次组卷积负责对主分组卷积的输出进行融合, 为卷 积。IGC模块形式上与深度可分离卷积类似,但分组的概念贯穿整个模块, 也是节省参数的关键,另外模块内补充了两个排序模块来保证channel间的信息交流。
IGC V2

IGC V1通过两个分组卷积来对原卷积进行分解,减少参数且保持完整的信息提取。但作者发现,因为主分组卷积和次分组卷积在分组数上是互补的,导致次卷积的分组数一般较小,每个分组的维度较大,次卷积核较为稠密。为此,IGC V2提出Interleaved Structured Sparse Convolution,使用多个连续的稀疏分组卷积来替换原来的次分组卷积,每个分组卷积的分组数都足够多,保证卷积核的稀疏性。
IGCV3
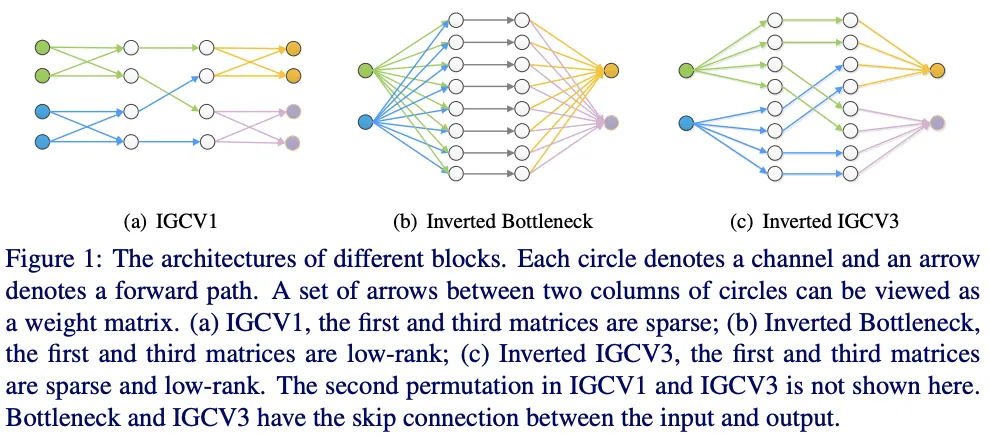
基于IGC V2和瓶颈(bootleneck)的思想,IGC V3结合低秩卷积核和稀疏卷积核来构成稠密卷积核,如图1所示,IGC V3使用低秩稀疏卷积核(bottleneck模块)来扩展和输入分组特征的维度以及降低输出的维度,中间使用深度卷积提取特征,另外引入松弛互补性原则,类似于IGC V2的严格互补性原则,用来应对分组卷积输入输出维度不一样的情况。
整体而言,虽然使用IGC模块后参数量和计算量降低了,但网络结构变得更为繁琐,可能导致在真实使用时速度变慢。
增加网络宽度
Inception Module是GoogLeNet的核心组成单元。其核心思想是将channel分成若干个不同感受野大小的通道,除了能获得不同的感受野,Inception还能大幅的降低参数数量。
Inception结构
Inception V1
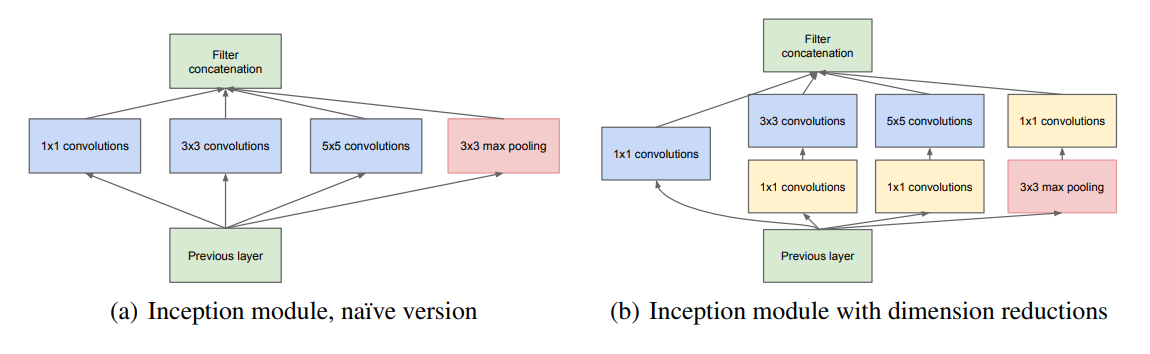
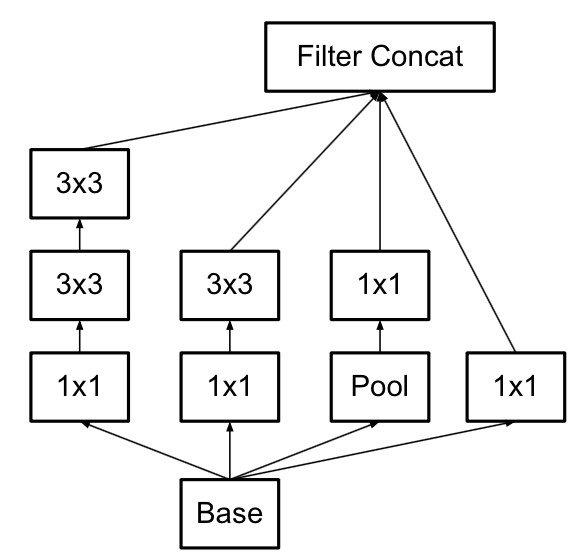
上图:一种Inception网路的示意。上图中(a)是Inception Module基本组成结构,其包含四个部分:卷积,卷积,卷积,最大池化。最后对四个成分运算结果进行通道上组合。
对于一个输入的Feature Map,首先通过三组卷积得到三组Feature Map,它和先使用一组卷积得到Feature Map,再将这组Feature Map分成三组是完全等价的(图2)。假设图1中卷积核的个数都是 , 的卷积核的个数都是 ,输入Feature Map的通道数为,那么这个简单版本的参数个数为:
对比相同通道数但是没有分组的普通卷积,普通卷积的参数量为:
这就是Inception Module的核心思想。通过多个卷积核提取图像不同尺度的信息,最后进行融合,可以得到图像更好的表征。
上图中(b)是对上述(a)的一种改进,即在卷积,卷积前加卷积,目的是为了先进行降维(减少了通道数),相比较于原来结构减少了较多参数:
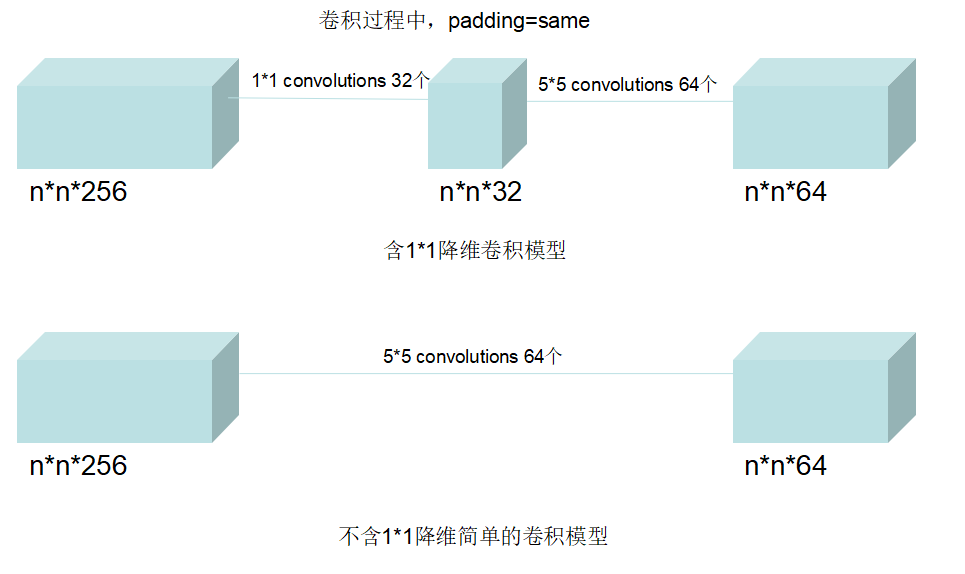
如上图所示,针对卷积的这一层,不包含的卷积模块时,参数量为:
连接数为:
而包含的卷积模块时,参数量为:
连接数为 :
而把卷积放在最大池化之后,相比较放在前面,也是为了参数量的减少。
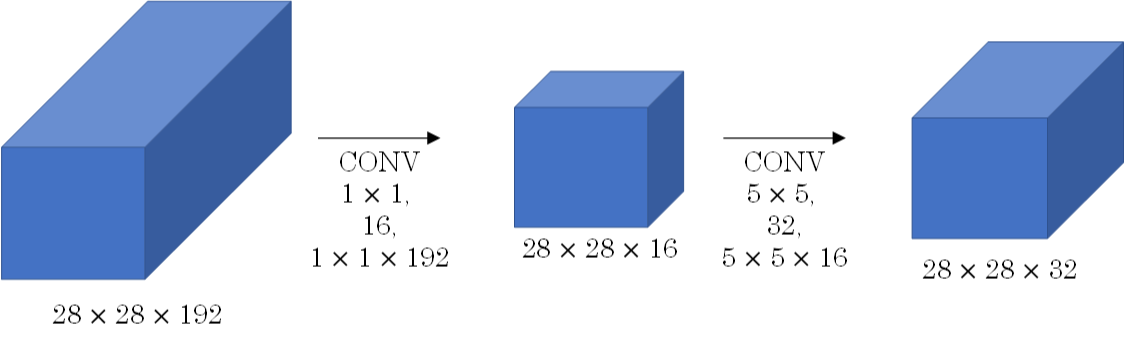
Inception V2
Inception V2学习了VGG使用代替卷积进一步减少计算量:
Inception V2 一方面了加入了BN层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯;另外一方面学习VGG用2个3x3的conv替代inception模块中的5x5,降低了参数数量加速计算。
Inception V3
学习Factorization into small convolutions的思想,将一个二维卷积拆分成两个较小卷积,例如将卷积拆成卷积和卷积:
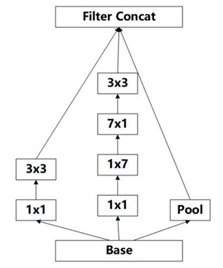
这样做的好处是降低参数量。paper中指出,通过这种非对称的卷积拆分(Factorization),比对称的拆分为几个相同的卷积效果更好,可以处理更多,更丰富的空间特征。论文指出,该设计使得网络结构得以进一步加深,并且增加了网络的非线性。
SqueezeNet
SqueezeNet是Han等提出的一种轻量且高效的CNN模型,它能够在ImageNet数据集上达到AlexNet近似的效果,但是参数比AlexNet少50倍。如果结合他们的模型压缩技术 Deep Compression,模型文件可比AlexNet小510倍。
SqueezeNet在设计上使用了以下三个理念:
- 大量使用卷积核替换卷积核,因为参数可以降低9倍。
- 减少3x3卷积核的输入通道数(input channels),这部分的设计在Fire模块(Fire Module)中使用,稍后会进行讲解。
- 延迟下采样(downsample),作者认为较大的Feature Map含有更多的信息,因此将降采样往分类层移动。注意这样的操作虽然会提升网络的精度,缺点是会增加网络的计算量。
SqueezeNet是由若干个Fire模块(Fire Module)结合卷积网络中卷积层,降采样层,全连接等层组成的。
Fire模块由Squeeze部分和Expand部分组成(注意区分和SENet中Squeeze过程的区别)。Squeeze部分是一组连续的卷积组成,Squeeze的目的是为了降低宽度上网络模块的输入量。Expand部分则是由一组连续的卷积和一组连续的卷积cancatnate组成,因此卷积需要使用的卷积。Fire模块的结构见下图:
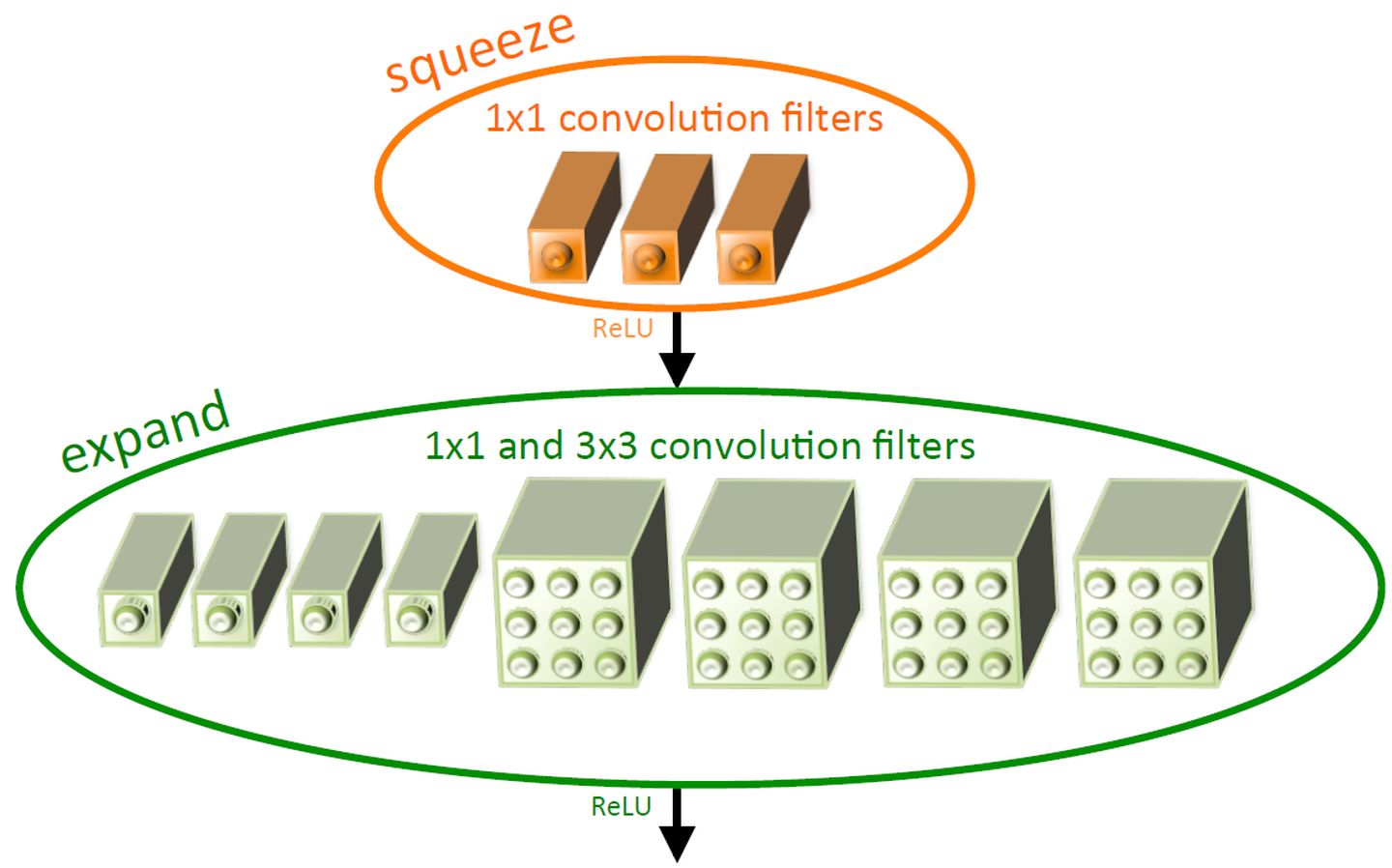
上图:Fire模块的设计。
在Fire模块中,Squeeze部分 卷积的通道数记做,Expand部分卷积和卷积的通道数分别记做和(论文图画的不好,不要错误的理解成卷积的层数)。在Fire模块中,作者建议 ,这么做相当于在两个卷积的中间加入了瓶颈层,作者的实验中的一个策略是。上图中,。
下面是Fire模块的代码片段:
def fire_model(x, s_1x1, e_1x1, e_3x3, fire_name):
# squeeze part
squeeze_x = Conv2D(kernel_size=(1,1),filters=s_1x1,padding='same',activation='relu',name=fire_name+'_s1')(x)
# expand part
expand_x_1 = Conv2D(kernel_size=(1,1),filters=e_1x1,padding='same',activation='relu',name=fire_name+'_e1')(squeeze_x)
expand_x_3 = Conv2D(kernel_size=(3,3),filters=e_3x3,padding='same',activation='relu',name=fire_name+'_e3')(squeeze_x)
expand = merge([expand_x_1, expand_x_3], mode='concat', concat_axis=3)
return expand
注意拼接Feature Map的时候使用的是concat操作,这样不必要求。
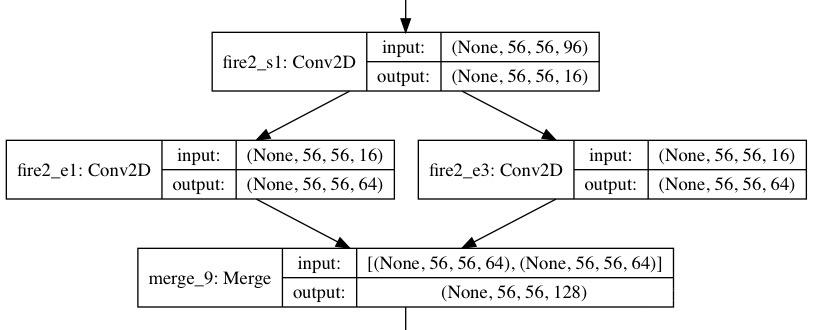
上图是这段代码片段的可视化。
SqueezeNext
SqueezeNext是SqueezeNet实战升级版,直接和MobileNet对比性能。SqueezeNext全部使用标准卷积,分析实际推理速度,优化的手段集中在网络整体结构的优化。
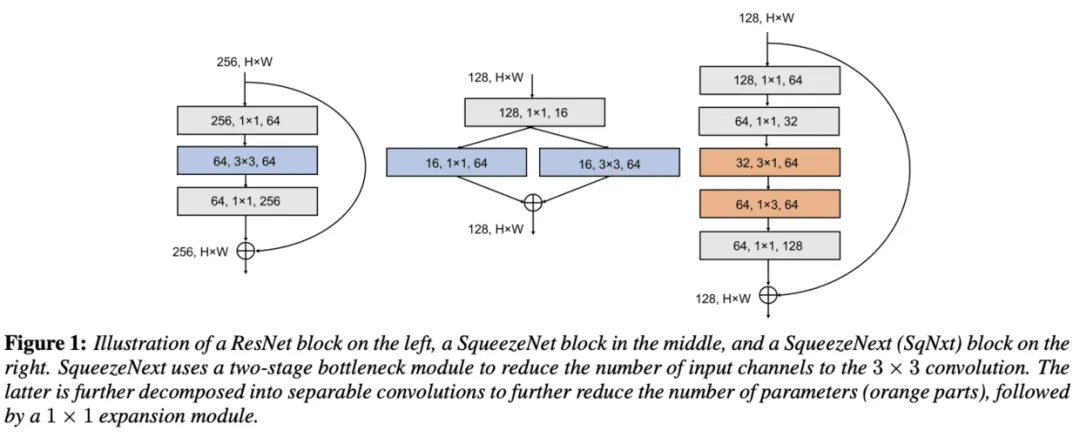
上图:SqueezeNext网络模块(右侧)设计与ResNet残差快(左侧)、SqueezeNet中的Fire模块(中间)的对比。可以看出,在设计中,SqueezeNext沿用残差结构,没有使用当时流行的深度分离卷积,而是直接使用了分离卷积。
深度可分离卷积
深度卷积(Depthwise convolution)
深度卷积(Depthwise convolution)最早是由Google提出,是指将输入特征图分为组(既Depthwise 是分组卷积的特殊简化形式),然后每一组做卷积,计算量为(是普通卷积计算量的,通过忽略通道维度的卷积显著降低计算量)。Depthwise相当于对于每个通道,单独使用一个仅属于该通道的卷积核。
上图:普通的卷积。

上图:深度卷积。
因为卷积操作的输出通道数等于卷积核的数量,而Depthwise Convolution中对每个通道只使用一个卷积核,所以单个通道在卷积操作之后的输出通道数也为1。那么如果输入feature map的通道数为N,对N个通道分别单独使用一个卷积核之后便得到N个通道为1的feature map。再将这N个feature map按顺序拼接便得到一个通道为N的输出feature map。
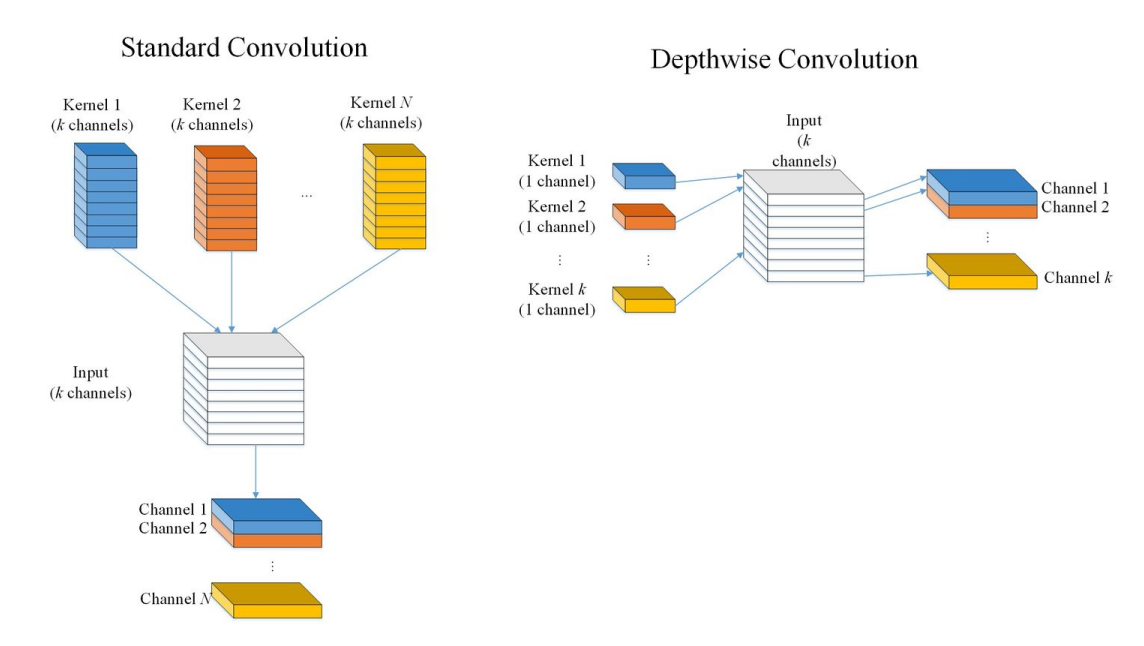
上图:Depthwise Convolution与普通卷积的直观对比。
对于计算性能,假设输入特征图的尺寸为,卷积核的大小为。在这里假设步长那么可知单个卷积核共需要进行次计算。所以对于一个卷积核,其计算量为:
如果使用普通卷积,若输出维度为,则对于个卷积核,其参数总量为:
也就是说,深度卷积是普通卷积参数量的。在这里由于深度卷积输入和输出的通道数相等,故,所以其参数量也可以写作普通卷积的。
逐点卷积(Pointwise Convolution)
逐点卷积(Pointwise Convolution)实际为1×1卷积,它的卷积核的尺寸为(是输入的通道数)。逐点卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map:
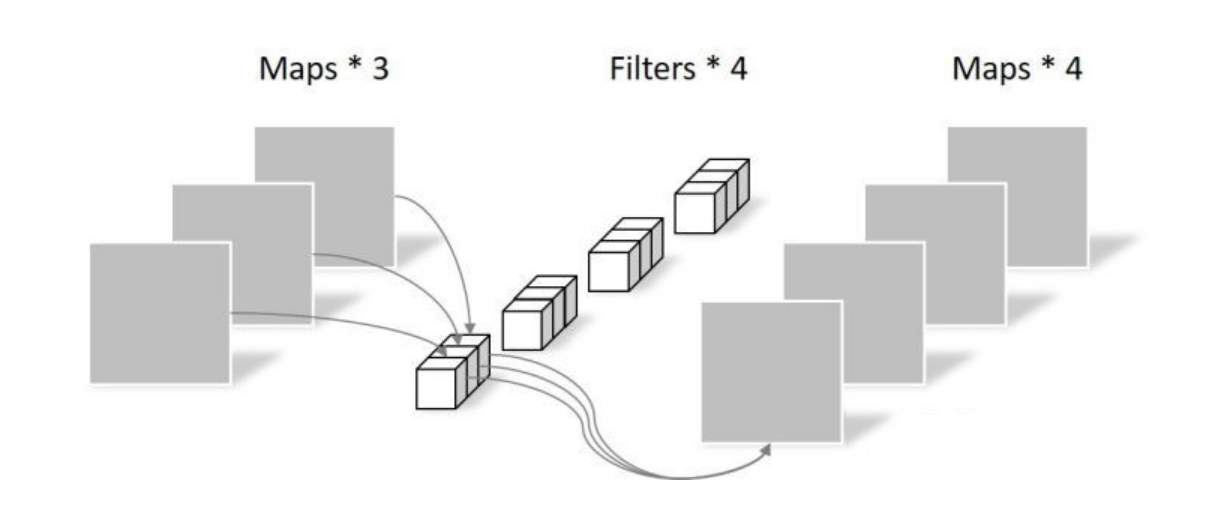
逐点卷积可以理解为在通道维度上的一维卷积。通过观察可以发现,逐点卷积中输出Feature map的数量等于卷积核的数量。
对于参数量,不难看出对于单个核,其参数量为上式中为卷积核尺寸。由于是在通道上进行的,所以。所以单个核的参数量为,即输入通道乘以输出通道。
对于其计算量,之前我们分析过普通卷积的单次计算量为:
而逐点卷积的计算量是:
所以逐点卷积的计算量是普通卷积的。
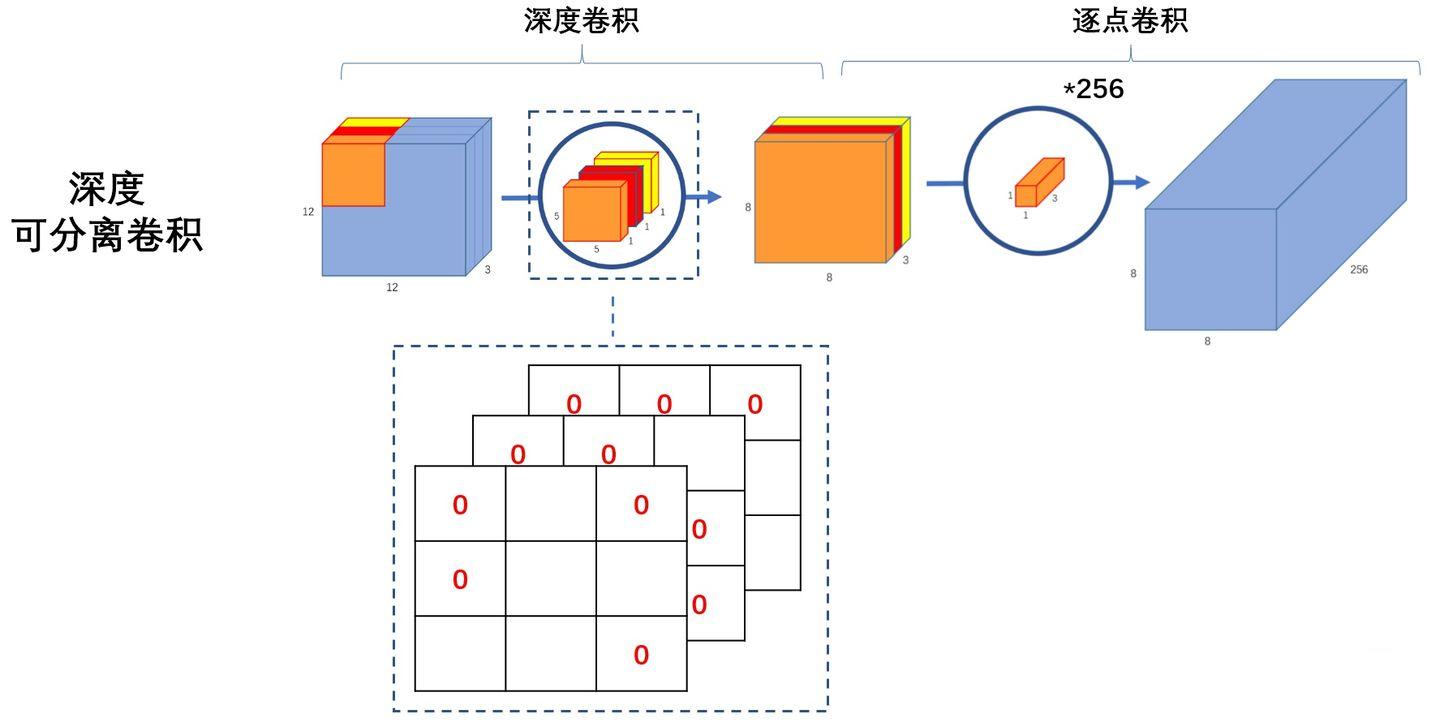
深度可分离卷积(Depthwise Separable Convolution)
深度可分离卷积(Depthwise Separable Convolution,DSC)可以理解为深度卷积(Deepwise Convolution)和逐点卷积(Pointwise Convolution)的串联:
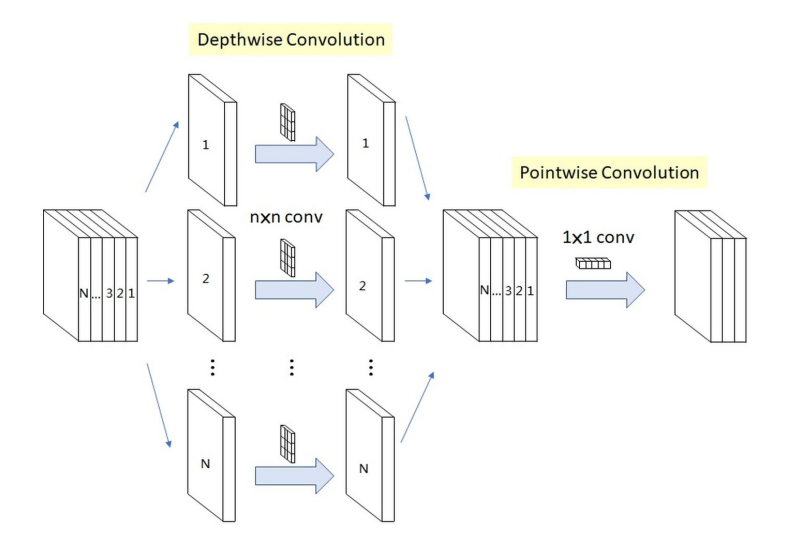
根据上文介绍的深度卷积和逐点卷积可以察觉,深度卷积仅对单个通道上的空间信息进行建模,并不会对通道间信息进行混合;而逐点卷积则恰好相反,仅对某个通道进行建模,而对每个通道的空间信息不做处理。深度可分离卷积将两者串联,使其同时具备混合空间和通道的能力。
上文中分析,深度卷积和逐点卷积计算量分别是普通卷积的和。对于上图中的情况,深度可分离卷积的计算量和普通卷积计算量的比值是。
这种结构最早出现在一篇名为Rigid-motion scattering for image classification的论文中。但让大家对DSC熟知的则是著名的MobileNet和Xception。
深度可分离卷积与Inception的关系
Inception和DSC在研究动机上的关系是:
Inception的假设是:图像的空间特征关系和通道间特征关系可以在一定程度上独立地计算;
DSC的假设是:图像的空间特征关系和通道间特征关系可以完全独立地计算。
Inception、DSC以及基于DSC的最著名的两个网络Xception和MobileNet均来自Google,所以它们之间存在非常密切的关系。关于Inception和DSC的动机,Xception这篇文章中有相关介绍。不过考虑到深度可分离卷积时间比较晚,所以这波也有可能是痛击友军。
MobileNet V1
MobileNetV1基于深度可分离卷积构建了非常轻量且延迟小的模型,并且可以通过两个超参数进一步控制模型的大小,该模型能够应用到终端设备中,具有很重要的实践意义。
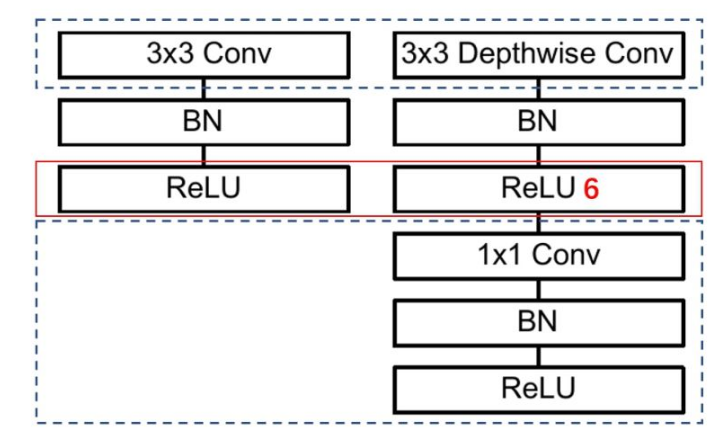
上图中左侧:标准的卷积单元;右侧:MobileNet V1中的网络单元。虚线处是不相同点。可以看出,MobileNet的网络单元首先使用3×3的深度卷积提取特征,接着是一个BN层,随后是一个ReLU层,在之后就会逐点卷积,最后就是BN和ReLU了。这也很符合深度可分离卷积,将左边的标准卷积拆分成右边的一个深度卷积和一个逐点卷积。注:ReLU6是一种ReLU的修改版本。作者认为ReLU6作为非线性激活函数,在低精度(fixed-point arithmetic)计算下具有更强的鲁棒性。
使用深度可分离的卷积对参数量的降低产生了显著的作用:

上图:使用标准卷积 VS 使用深度可分离卷积。
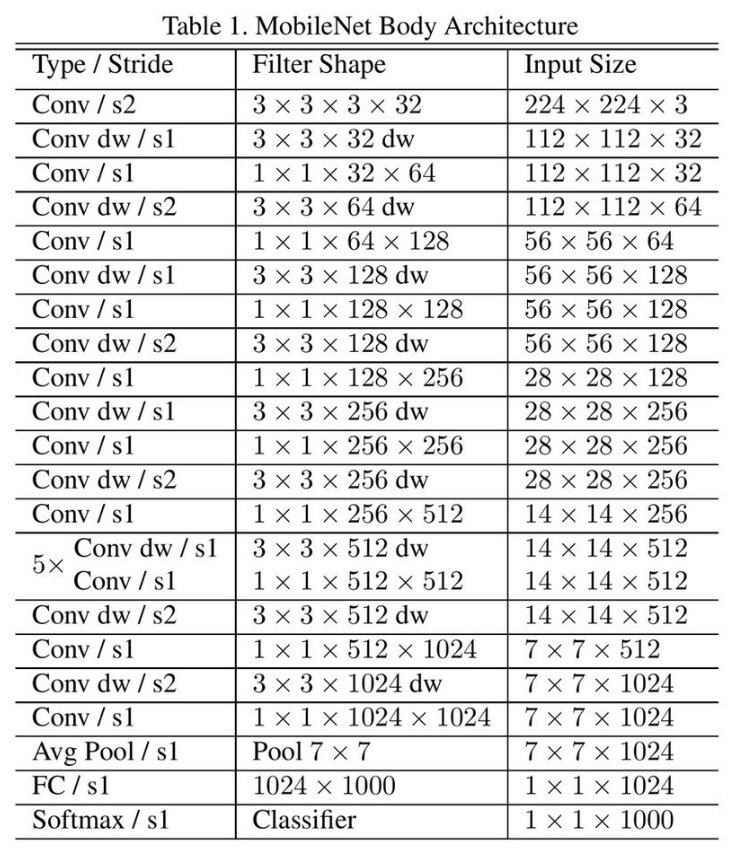
上表:MobileNet V1的网络结构。首先是一个的标准卷积,进行下采样。然后就是堆积深度可分离卷积,并且其中的部分深度卷积会利用进行下采样。然后采用平均池化层将feature变成,根据预测类别大小加上全连接层,最后是一个softmax层。整个网络有28层,其中深度卷积层有13层。

可以发现,作为轻量级网络的MobileNet V1在计算量小于GoogleNet,参数量差不多是在一个数量级的基础上,在分类效果上比GoogleNet还要好。注:当时的ImageNet参数还是可以信一下的。
Xception: Extream Inception
Xception被称为极端的Inception。如果Inception是将卷积分成3组,那么考虑一种极端的情况,我们如果将Inception的 得到的个通道的Feature Map完全分开呢?也就是使用个不同的卷积分别在每个通道上进行卷积,它的参数数量是:
更多时候我们希望两组卷积的输出Feature Map相同,这里我们将Inception的卷积的通道数设为,即参数数量为
它的参数数量是普通卷积的,我们把这种形式的Inception叫做Extreme Inception:
将Inception和Xception放在一起有助于观察其相关性:
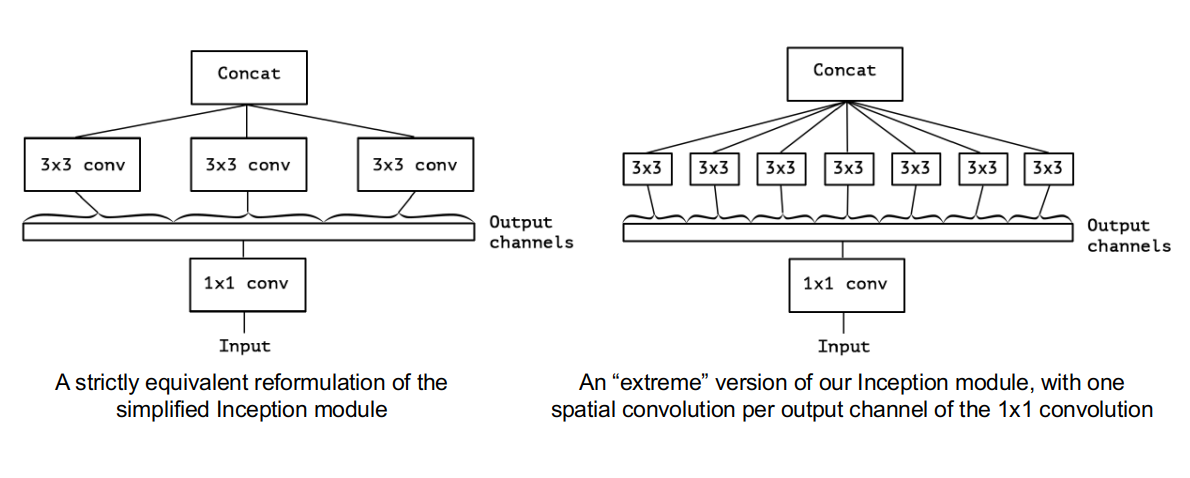
左:Inception示意;右:Xception。
深度可分离卷积和Xception不完全相同。区别之一就是先计算Point-wise卷积还是先计算Deep-wise卷积的问题;另一个区别是Xception是线性的,而深度可分离的卷积不严格线性。
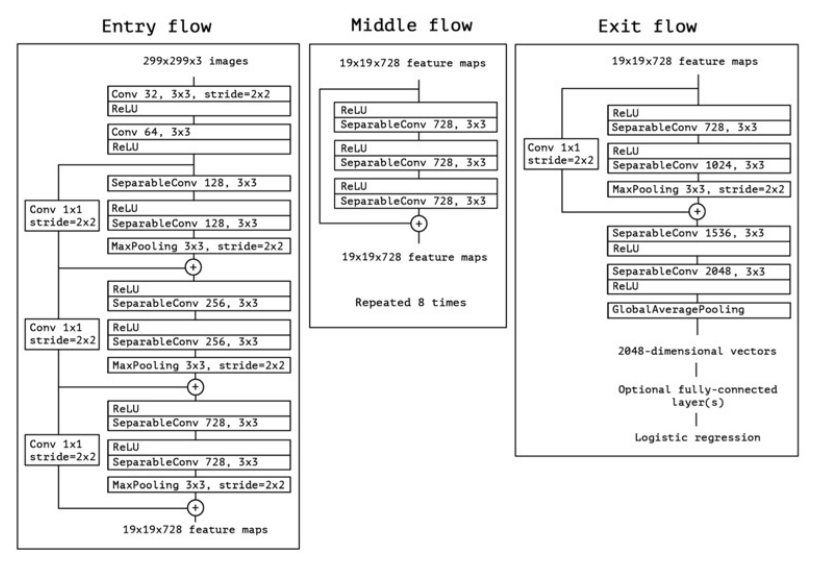
上图:结合残差结构,一个完整的使用Xception的网络。
请不要在低维乱激活
低维空间可以简单理解为channel数比较少的情况。在低维乱激活,举个例子,你将通道数为3的特征图传入了激活层。这样做容易引起训练参数出现崩塌的情况。在轻量级网络设计中,在较浅层的网络进行激活、进行疯狂的通道裁剪、使用深度可分离的卷积等都可能导致奇怪的问题。
MobileNet V1 出现的训练时崩坏
MobileNetV1既能较少不小的参数量、计算量,提高网络运算速度,又能的得到一个接近于标准卷积的还不错的结果,看起来是很美好的。但是,有人在实际使用的时候, 发现深度卷积部分的卷积核在训练中比较容易“失效”:训完之后发现深度卷积训出来的卷积核有不少值是0:
在MobileNet V2的论文中,作者称网络层中的激活特征为兴趣流形(mainfold of interest),论文中有如下观点:
It has been long assumed that mainfolds of interest in neural networks could be imbedded in low-dimensional subspaces. In other words, when we look at all individual d-channel pixels of a deep convolutional layer, the information encoded in those values actually lie in some mainfold, which in turns is embeddable into a low-dimensional subspace.
通俗点说,我们查看的卷积层中所有单个通道像素时,这些值中存在多种编码信息,兴趣流行位于其中。我们可以通过变换,进一步嵌入(Embade)到下一个低维子空间中。
但是,由于网络中存在非线性的激活函数,以ReLU变换为例,存在一个特性:如果当前激活空间内兴趣流形完整度较高,经过ReLU,可能会让激活空间坍塌,不可避免的会丢失信息。

上图:将低维流形的ReLU变换embeding到高维空间中的的例子(如果你不了解Embedding,可以查看这篇文章)。如图所示,Input是一个2维数据,其中兴趣流形是其中的蓝色螺旋线。本例使用矩阵将数据嵌入到n维空间中,后接ReLU,再使用其逆矩阵将其投影回原空间。
可以观察到,当时,与Input相比有很大一部分的信息已经丢失了。而当,还是有相当多的分布信息被恢复回来。
回想深度可分离卷积中有关深度的部分,在单个通道上的ReLU运算就是对低维度做ReLU运算。根据上面的说法,对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。这也是轻量级网络设计应该注意和避免的拟合空间中容易出现的问题。
这就解释了为什么深度卷积的卷积核有不少是空。发现了问题,我们就能更好地解决问题。针对这个问题,可以这样解决:既然是ReLU导致的信息损耗,将ReLU替换成线性激活函数。
MobileNet V2:使用线性瓶颈(Linear Bottleneck)和反残差(Inverted Residuals)对抗崩坏
瓶颈(Bottleneck)层来源于ResNet,其设计本源是为了避免在残差网络中巨大的计算量。线性瓶颈(Linear Bottleneck)层的设计则源于MobileNet V2,目的是为了解决在MobileNet V1中出现的训练时崩坏问题。
线性瓶颈是使用卷积实现的。其目的是为了在网络进入深度卷积(Depthwise Convolution)之前对特征先进行升维,之后再进行降维恢复其原通道数。升维的卷积被称为“Expantion Layer”,降维的卷积被称为“Projection Layer”。这样叫大概就是因为想表示这是在做Embedding吧。
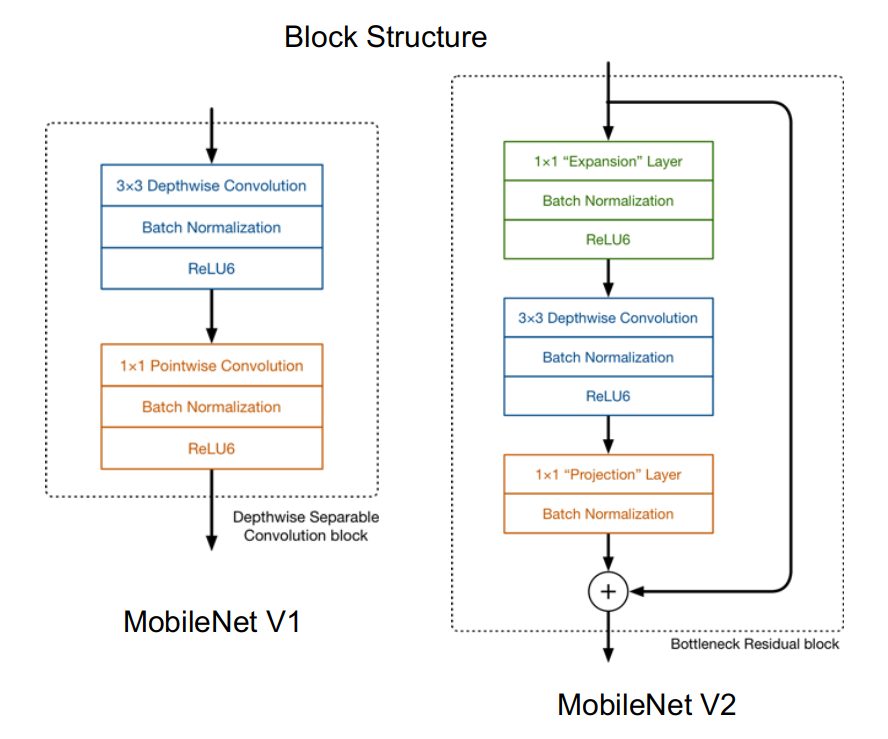
上图:MobileNet V1和MobileNet V2网络基础块结构的对比。所以实际上,MobileNet V2中提出的线性瓶颈层(对特征进行了升维)作用和ResNet中的瓶颈层(对特征进行了降维)效果完全相反:
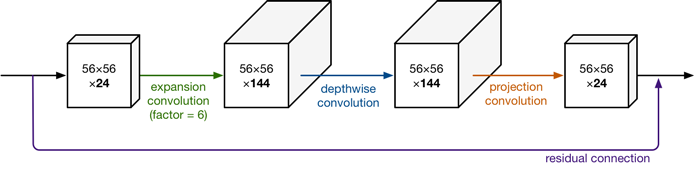
上图详细的展示了整个模块的结构。输入是24维,最后输出也是24维。但这个过程中,特征图被扩展了6倍(),然后应用深度可分离卷积进行处理。整个网络是中间胖,两头窄,像一个纺锤形。bottleneck residual block(ResNet论文中的)是中间窄两头胖,在MobileNetV2中正好反了过来,所以,在MobileNetV2的论文中我们称这样的网络结构为Inverted residuals。需要注意的是residual connection是在输入和输出的部分进行连接。
可以作出以下简单的理解:
MobileNet V1 网络块的结构为:
- Depthwise convolution
- Pointwise convolution
MobileNet V2 网络块的结构为:
- Pointwise convolution(Expantion Layer)
- Depthwise convolution
- Pointwise convolution(Projection Layer)
-上述修改使得特征空间先升维,再进行ReLU计算,其后再进行降维。从而避免了在MobileNet V1中出现的问题。
EfficientNet:模型缩放
在本篇论文中,我们系统地研究了模型缩放并且仔细验证了网络深度、宽度和分辨率之间的平衡可以导致更好的性能表现。
目前通用的几种方法是放大CNN的深度、宽度和分辨率,在之前都是单独放大这三个维度中的一个,尽管任意放大两个或者三个维度也是可能的,但是任意缩放需要繁琐的人工调参同时可能产生的是一个次优的精度和效率。
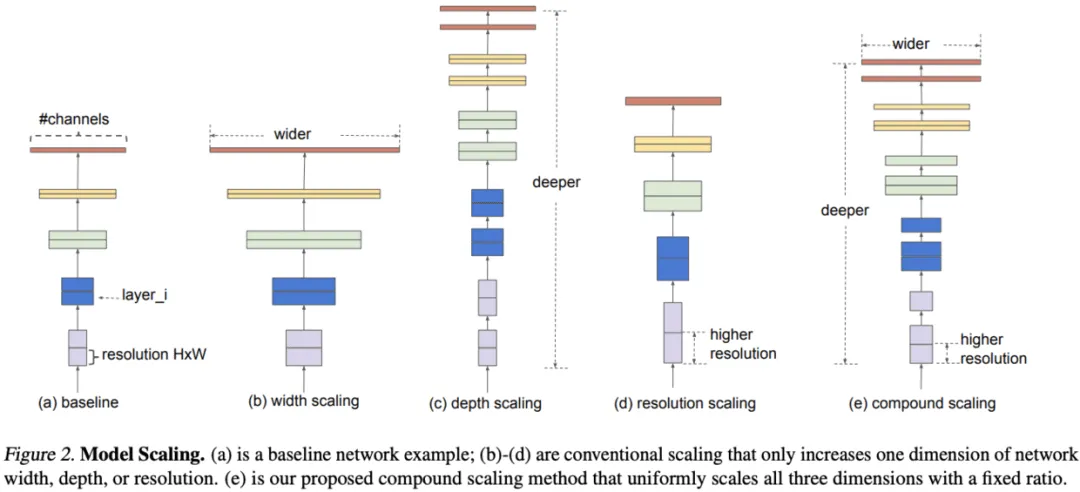
上图:在深度、宽度、分辨率等角度上进行模型缩放的示意。
直观来讲,如果图像尺寸变大,复合的缩放方法会很有意义,因为当图像尺寸变大意味着网络需要更多层来增加接受野,同时需要更多的通道来捕捉更大图像上更多细粒度的模式信息。
GhostNet:特征有效性的探究
训练好的网络一般都有丰富甚至冗余的特征图信息来保证对输入的理解,相似的特征图类似于对方的ghost。但冗余的特征是网络的关键特性,论文认为与其避免冗余特征,不如以一种cost-efficient的方式接受,于是提出能用更少参数提取更多特征的Ghost模块,首先使用输出很少的原始卷积操作(非卷积层操作)进行输出,再对输出使用一系列简单的线性操作来生成更多的特征。这样,不用改变其输出的特征图数量,Ghost模块的整体的参数量和计算量就已经降低了。
神经网络搜索
MobileNet V3
MobileNet V3的论文名称为“Searching for MobileNetV3”。“searching”一词就把V3的论文的核心观点展示了出来——用神经结构搜索(NAS)来完成V3。
MobileNetV3先基于AutoML构建网络,然后进行人工微调优化,搜索方法使用了platform-aware NAS以及NetAdapt,分别用于全局搜索以及局部搜索,而人工微调则调整了网络前后几层的结构、bottleneck加入SE模块以及提出计算高效的h-swish非线性激活。
"抱歉,有钱真的可以为..."
实在没钱,没接触过NAS,等有机会弄懂了再回来补上。
FBNet系列
FBNet V1
FBNet V2
FBNet V3
使用动态神经网络
WeightNet
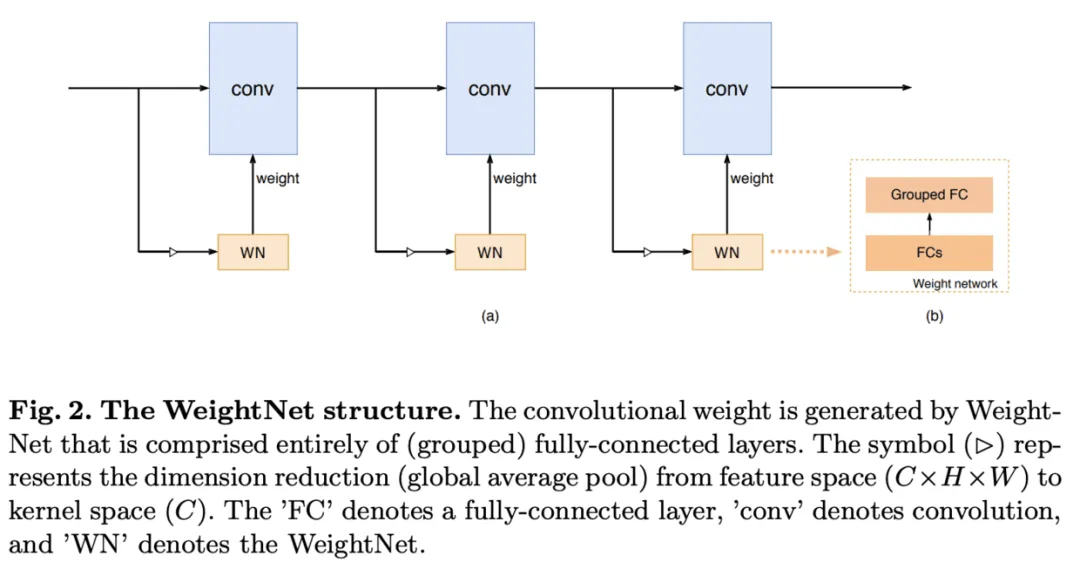
论文提出了一种简单且高效的动态生成网络WeightNet,该结构在权值空间上集成了SENet和CondConv的特点,在激活向量后面添加一层分组全连接,直接产生卷积核的权值,在计算上十分高效,并且可通过超参数的设置来进行准确率和速度上的trade-off。
MicroNet
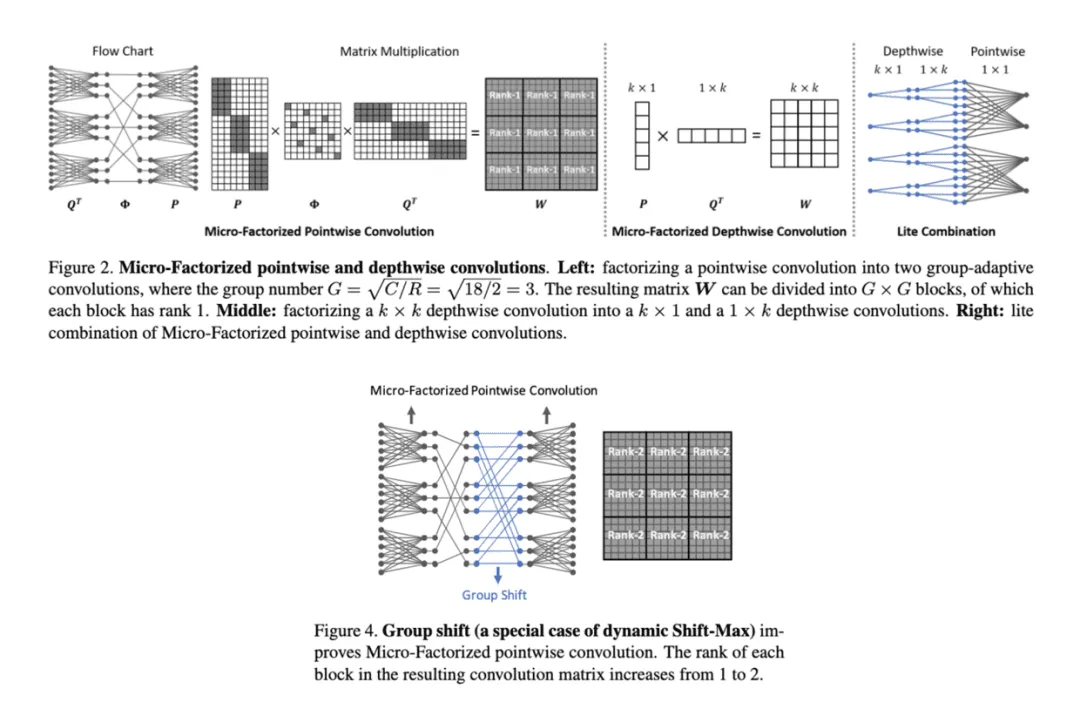
论文提出应对极低计算量场景的轻量级网络MicroNet,包含两个核心思路Micro-Factorized convolution和Dynamic Shift-Max,Micro-Factorized convolution通过低秩近似将原卷积分解成多个小卷积,保持输入输出的连接性并降低连接数,Dynamic Shift-Max通过动态的组间特征融合增加节点的连接以及提升非线性,弥补网络深度减少带来的性能降低。